One of the most important notions in mathematics (and also very important in physics) is the one of a representation. It is key to understand complicated spaces by means of a simpler object and to exploit notions from linear algebra. In some sense, linear algebra is the only thing that we understand so far, linearity is easy to comprehend, hence we try to explain everything else in terms of linearity, everything that is non-linear is somewhat is a dark matter, like a voodoo or black magic that we can try to understand by approximating it using linear things. The idea of a representation provides one of these approximations.
Since my first semesters in grad school I learnt the definition of a representation, but it always appear to me as very strange and made up, something a bit unreal and artificial (as many things in algebra) and I never got a true feeling of what it really was.
I guess I am somehow a kind of more geometric-oriented person, so I try to visualize object in order to understand them (hence me being bad at algebra).

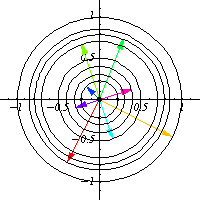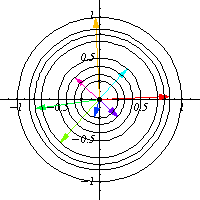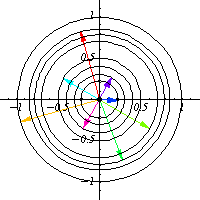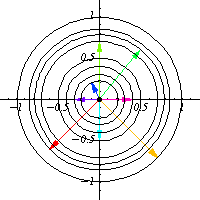
I tried understanding a simple example first: The action of $S^1$ on $\mathbb{C}$ by the standard multiplication on the complex plane. This is just a fancy way to say that it acts by rotation, that is, given $z\in S^1$ viewed as a complex number, it acts on any complex number $w$ by $w\mapsto zw$. Therefore, for any point in $z$, we have a map $R_z$ that rotates the complex plane by an angle of $\arg z$.

This is the same as thinking that over every point $z$ on $S^1$ we have a rotated version of the complex plane $\mathbb{C}$, which can be visualized as a cardiod. One can say then that the cardiod is in some sense the graph of the action of $S^1$ over $\mathbb{C}$.
To be a bit more technical, we can consider 1 (complex) dimensional vector bundle over $S^1$ where the fibers rotate depending on $z$, and the action can be viewed as a section of this vector bundle with the property that agrees with the group structure of the base.
Hence a representation can be realized as as a section of a vector bundle over the group that agrees with the group structure, that is, a homomorphism, i.e., the fiber at any point on the group can be obtained by translating the fiber at the identity to the fiber at the point.